Author: Sergey Lukyanchikov, Sales Engineer at InterSystems
What is Distributed Artificial Intelligence (DAI)?
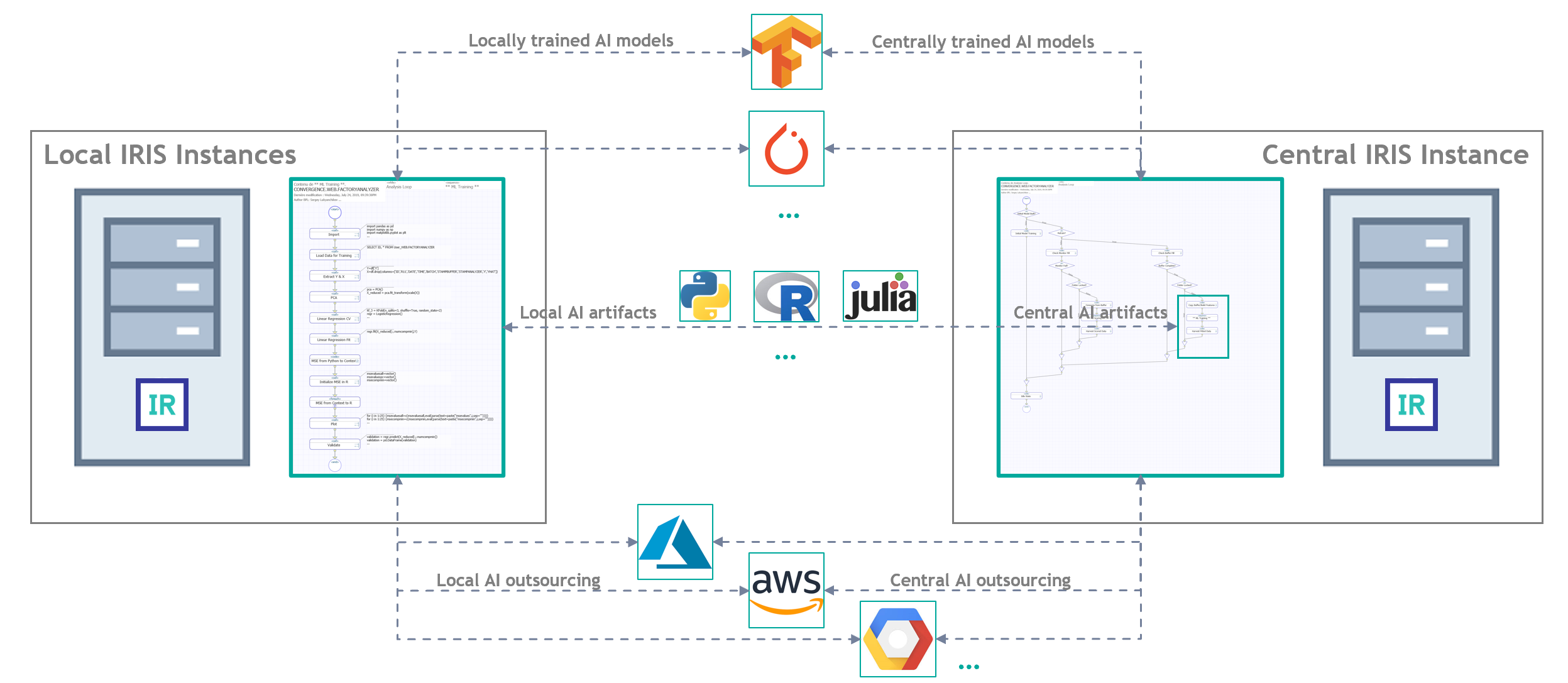
Attempts to find a “bullet-proof” definition have not produced result: it seems like the term is slightly “ahead of time”. Still, we can analyze semantically the term itself – deriving that distributed artificial intelligence is the same AI (see our effort to suggest an “applied” definition) though partitioned across several computers that are not clustered together (neither data-wise, nor via applications, not by providing access to particular computers in principle). I.e., ideally, distributed artificial intelligence should be arranged in such a way that none of the computers participating in that “distribution” have direct access to data nor applications of another computer: the only alternative becomes transmission of data samples and executable scripts via “transparent” messaging. Any deviations from that ideal should lead to an advent of “partially distributed artificial intelligence” – an example being distributed data with a central application server. Or its inverse. One way or the other, we obtain as a result a set of “federated” models (i.e., either models trained each on their own data sources, or each trained by their own algorithms, or “both at once”).
Distributed AI scenarios “for the masses”
We will not be discussing edge computations, confidential data operators, scattered mobile searches, or similar fascinating yet not the most consciously and wide-applied (not at this moment) scenarios. We will be much “closer to life” if, for instance, we consider the following scenario (its detailed demo can and should be watched here): a company runs a production-level AI/ML solution, the quality of its functioning is being systematically checked by an external data scientist (i.e., an expert that is not an employee of the company). For a number of reasons, the company cannot grant the data scientist access to the solution but it can send him a sample of records from a required table following a schedule or a particular event (for example, termination of a training session for one or several models by the solution). With that we assume, that the data scientist owns some version of the AI/ML mechanisms already integrated in the production-level solution that the company is running – and it is likely that they are being developed, improved, and adapted to concrete use cases of that concrete company, by the data scientist himself. Deployment of those mechanisms into the running solution, monitoring of their functioning, and other lifecycle aspects are being handled by a data engineer (the company employee).